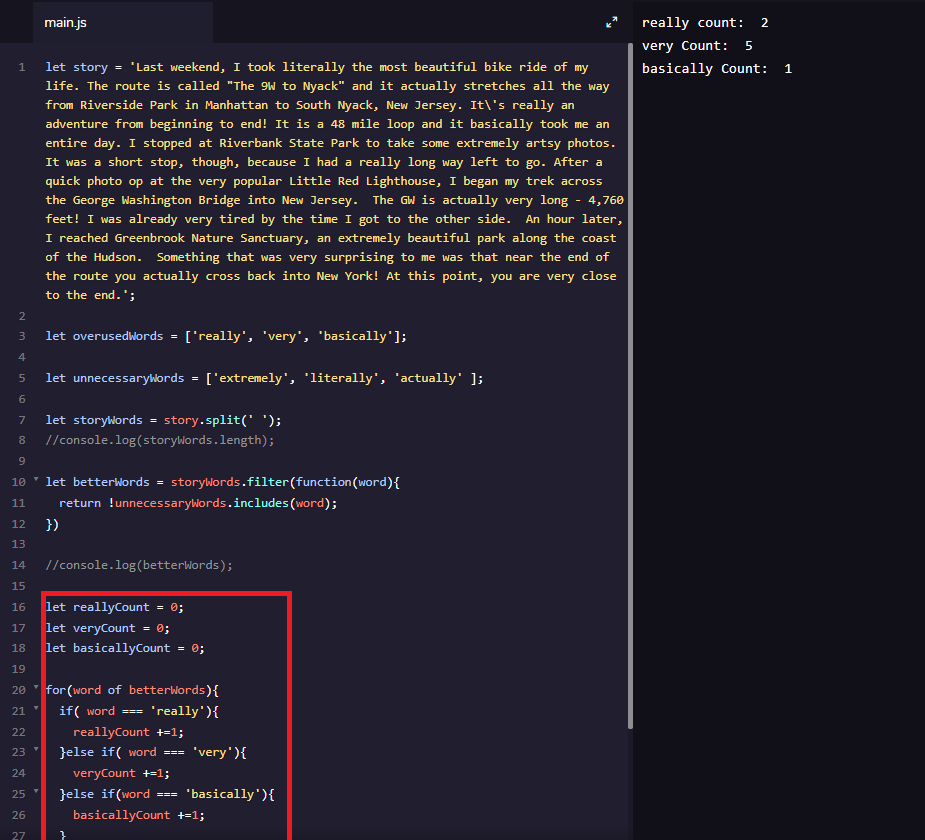
Mi se da string-ul story pe care apoi il sparg in cuvinte separate si il pun in array-ul storyWords apoi din acest array scot cuvintele care se afla in unnecessaryWords. Toate bune si frumoase pana aici, dar apoi imi cere sa verific de cate ori apare fiecare cuvant in parte din array-ul overusedWords in storyWords. In chenarul rosu este rezolvarea data de ei. Problema care imi da de cap este ce se intampla daca de exemplu in overusedWords am 100 de cuvinte?
Imi poate arata cinvea o rezolvare?
Am incercat sa fac asta, dar eu vreau sa-mi afiseze pentru fiecare cuvant in parte de cate ori a fost folosit in array1, ca in coltul din dreapta sus a imaginii:
really count: 2
very Count: 5
basically Count: 1
Pare a fi o problema clasica care se rezolva cu vector de frecventa
let story = "really very basically bla bla ba afara este frig. Ana are mere. Javascript drives me very mad. But basically it is used everywhere";
let overUsedWords = ["really", "very", "basically"]
let storyWords = story.split(" ");
let freq = {}
for (word of storyWords)
{
if(word === overUsedWords[0] || word === overUsedWords[1] || word === overUsedWords[2])
{
if(freq[word])
{
freq[word]++
}
else
{
freq[word] = 1;
}
}
}
console.log(freq);
Cel putin asta ar fi idea mea. Asta daca am inteles bine
LE:
let story = "really very basically bla bla ba afara este frig. Ana are mere. Javascript drives me very mad. But basically it is used everywhere. Very Ana Ana Ana really";
let overUsedWords = ["really", "very", "basically", "Ana"];
let storyWords = story.split(" ");
let freq = {}
for (storyWord of storyWords)
{
for(overUsedWord of overUsedWords)
{
if(storyWord.toLowerCase() === overUsedWord.toLowerCase())
{
if(freq[overUsedWord])
{
freq[overUsedWord]++;
}
else
{
freq[overUsedWord] = 1;
}
}
}
}
console.log(freq);
Abordarea este în aceeași tema ca mai sus, dar nu mai verific frecventa tuturor cuvintelor ci doar cele din overUsedWords. Când lucrezi cu text și stringuri ar trebui sa lucrezi cu litere ori mici, ori mari.
Exemplu: Daca în acel text aveai “…Very…” și nu apărea în overUsedWords, nu era luat în considerare
Super! A mers. Nu m-am gandit la rezolvarea asta. Mai trebuie un for care sa-mi parcurga overusedWords ca sa functioneze corect in cazul in care acest array are mai multe cuvinte. Si da, ai dreptate, e bine de luat in calcul si faza cu litera mare/mica.
Multumesc mult de ajutor!