Evident, într-o bază de date reală probabil ar fi tabele separate pentru useri dar am simplificat pentru că nu ăsta e scopul.
Și acum query-ul:
WITH accumulate_users AS (
SELECT DISTINCT
p1.user_name AS user_name,
p2.post_date AS post_date
FROM
posts p1
INNER JOIN posts p2 ON (TRUE)
WHERE
(
SELECT
COUNT(*)
FROM
posts tmp
WHERE
tmp.user_name = p1.user_name
AND tmp.post_date <= p2.post_date
) > 0
ORDER BY
p2.post_date, p1.user_name
),
get_counts AS (
SELECT
CASE
WHEN t.user_name = 1 THEN 'A'
WHEN t.user_name = 2 THEN 'B'
WHEN t.user_name = 3 THEN 'C'
ELSE 'Unkown'
END user_name,
t.post_date AS date_posted,
(
SELECT
COUNT(*)
FROM
posts p
WHERE
p.post_date <= t.post_date
AND p.user_name = t.user_name
) AS number_of_posts
FROM
accumulate_users t
ORDER BY
t.post_date ASC, number_of_posts DESC
)
SELECT * FROM get_counts;
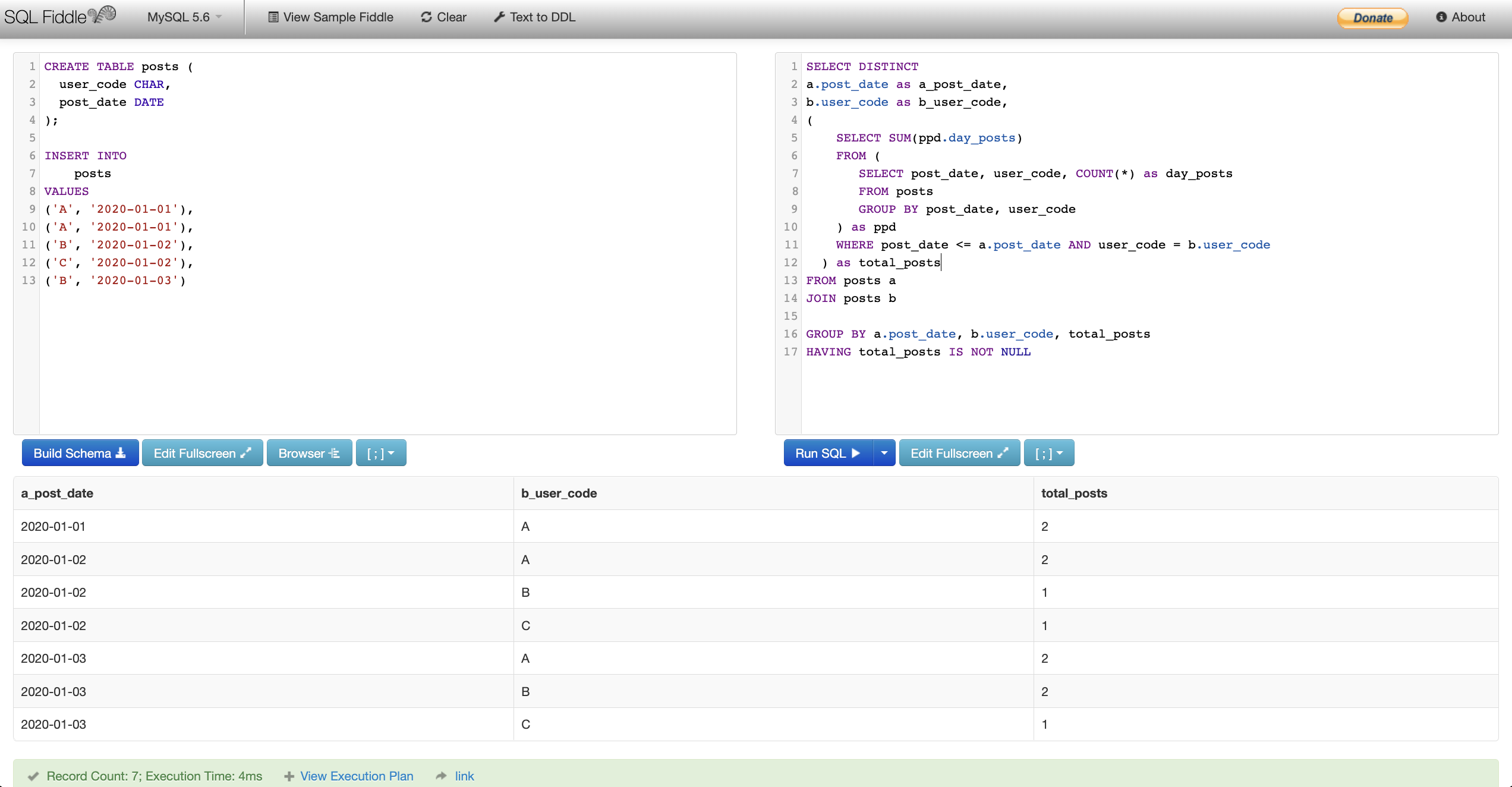
SELECT DISTINCT
a.post_date as a_post_date,
b.user_code as b_user_code,
(
SELECT SUM(ppd.day_posts)
FROM (
SELECT post_date, user_code, COUNT(*) as day_posts
FROM posts
GROUP BY post_date, user_code
) as ppd
WHERE post_date <= a.post_date AND user_code = b.user_code
) as total_posts
FROM posts a
JOIN posts b
GROUP BY a.post_date, b.user_code, total_posts
HAVING total_posts IS NOT NULL
Nu cred ca exista din simplul fapt ca daca vrei ca sa ai mai multe rezultate in final, decat sunt in tabelul sursa, e imposibil sa faci asta fara un self join.
Pornind doar de la un SELECT O(n), vei obtine un numar maxim de rezultate cu cel care este in tabelul sursa. Asta daca nu faci nici o filtrare/limitare/grupare.
Ce poti face in schimb, este sa ai un tabel/view separat in care sa introduci aceste date in formatul de care ai nevoie, astfel incat sa le poti selecta cu o complexitate de O(n).
Poti tine up-to-date acel view/tabel folosind functionalitate de TRIGGER de care dispunea baza de date.
Păi rezultatul cuprinde aproximativ numărul de useri ori numărul de dăți în care a fost postat ceva, deci nu prea văd cum ar arăta ceva eficient, având în vedere câte rezultate trebuiesc afișate. Mai degrabă aș vedea niște optimizări la nivel de aplicație, adică să se evite o astfel de statistică cât mai mult. De exemplu pentru a calcula pentru o singură dată se poate face mult mai eficient. Și poate e necesar doar pentru un user, nu toți neapărat. Și poate se poate face cumva astfel încât rezultatele să fie încărcate on-demand folosind queries mai eficiente, nu încărcat totul dinainte. Altfel, nu văd un astfel de query scalând prea bine.