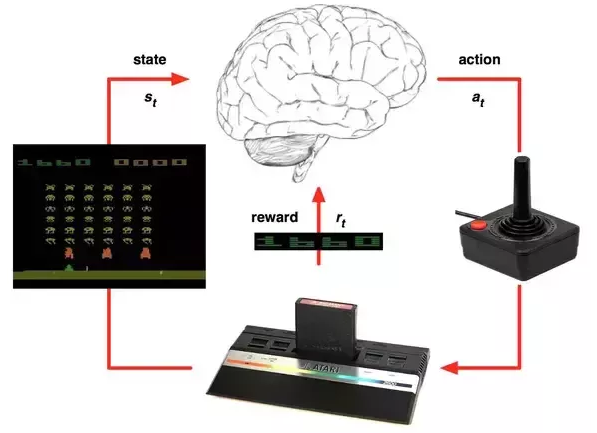
Reinforcement learning este o tehnica prin care un agent AI invata prin cautare maximizare reward, efectiv incearca trial error si in functie de rezultat primeste un feedback pe care il evalueaza ca reward pozitiv sau negativ, sunt cateva exemple in tutorial cum un neural network + reinforcement learning pot face un agent AI sa invete sa indeplineasta anumite task-uri.
Unii considera ca reinforcement learning este calea catrea true AI, se fac anumite studii la OpenAI, compania fondata de Elon Musk.
Researchers at Facebook realized their bots were chattering in a new language. Then they stopped it.
Doi agenti AI trebuiau sa negocieze pentru indeplinirea unui task, desi au fost programati sa comunice in engleza si-au dezvoltat propiul limbaj pentru a comunica, deoarece functia de reward nu implica comunicarea in engleza.
Se da un graf si se doreste ca salesman sa ajunga din nodul X in nodul Y(o variatie a problemei) cu cost minim, o solutie euristica este sa se aleaga la fiecare pas path-ul optim, aceasta duce la un optim local care poate diferi de optim global, tehnica se numeste Greedy.
the agent occupies a position in a 5x5 grid, and the delivery destination occupies another position. The agent can move in any of four directions (up, down, left, right). If we want our drone to learn to deliver packages, we simply provide a positive reward of +1 for successfully flying to a marked location and making a delivery.
AlphaStar este urmasul lui AlphaGo, AI-ul care la batut pe campionul mondial la Go, unul dintre cele mai complexe jocuri, AlphaStar este un AI care se concentreaza sa concureze cu jucatori profesionisti la jocuri pe calculator in cazul asta Starcraft, lansarea este recenta 24 January 2019.
Mastering this problem requires breakthroughs in several AI research challenges including:
Game theory: StarCraft is a game where, just like rock-paper-scissors, there is no single best strategy. As such, an AI training process needs to continually explore and expand the frontiers of strategic knowledge.
Imperfect information: Unlike games like chess or Go where players see everything, crucial information is hidden from a StarCraft player and must be actively discovered by “scouting”.
Long term planning: Like many real-world problems cause-and-effect is not instantaneous. Games can also take anywhere up to one hour to complete, meaning actions taken early in the game may not pay off for a long time.
Real time: Unlike traditional board games where players alternate turns between subsequent moves, StarCraft players must perform actions continually as the game clock progresses.
Large action space: Hundreds of different units and buildings must be controlled at once, in real-time, resulting in a combinatorial space of possibilities. On top of this, actions are hierarchical and can be modified and augmented. Our parameterization of the game has an average of approximately 10 to the 26 legal actions at every time-step.
Un rezumat care mi se pare interesant, AI este un domeniu in care se face Research de prin 1950, sunt carti din aceas perioada de exemplu cea scrisa de Marvin Minsky, The Society of Mind, el a fondat la MIT laboratorul de AI, AI a trecut prin 2 Winters: 1970, 1980,
si a avut 3 etape:
1.) Classical AI
2.) Knowledge Driven AI
3.) Data Driven AI (faza curenta)
Cele 2 Winters s-a datorat faptului ca rezultatele nu erau cele asteptate si sistemele expert AI erau foarte greu de intretinut.
O clasificare AI ar fi
1.) General Artificial Intelligence (aici sunt companii ca DeepMind, OpenAI), unde AI ar trebui sa fie capabil de mai multe sarcini, Reinforcement Learning combinat cu Deep Learning pare sa se incadreze la General Artificial Intelligence.
2.) Narrow Artificial Intelligence, AI care sunt capabile de un singur task, exemplu: computer vision, speech recognition, etc, machine learning este inclus in AI, AI reprezentand o clasa mai mare.
.
Si desigur autorul prezinta frameworks ca si Tensorflow, Pythorch, de multe ori trebuie doar refolosit ce exista, un algoritm sau o platforma: Azure, Amazon, Google.
Eu personal am o Alexa, are o gramada de skills pe store si poti sa ii dezvolti skill-uri noi.