Cum zice și @iamntz ar fi ok să scoți numele providerului din titlu pentru că aici nu e vina lor, iar business-ul se construiește greu și se dărâmă mult mai ușor.
Pune și tu un cloudflare peste dacă nu ai, iar pentru servicii critice în producție se folosește de obicei firewall hardware, care e destul de costisitor.
Altfel, poți să te documentezi pe tema asta în a-ți face singur un mini firewall pentru boți și bălării de genul, poți angaja pe cineva sau poți cumpăra resurse managed.
În cazul de faţă firewall-ul nu ajută deloc. Atacul vine pe portul http/https şi nu ai cum să blochezi portul ăla fără să blochezi complet serviciul. Cel mult ai putea pune o regulă de tip rate limit, care să limiteze numărul de accesări în unitatea de timp.
Sustin si eu varianta cu CloudFlare ca fiind una din cele mai simple/rapide de implementat in asemenea situatii. Se pune paravan intre atacatori si serverle tale, ascunzandu-ti IP-ul real al serverului tau. Singura problema e la MX records, unde IP-ul nu se poate proxy-ui si trebuie sa fie vizibil ca sa-ti functioneze serverul de mail. In acea situatie se recomanda ca serverul de mail sa fie pe un server separat fata de cel cu aplicatia.
Nu prea văd cu ce ar ajuta un paravan în situaţia de scan-uri brute-force. CloudFlare nu are de unde să ştie că e o scanare şi va permite request-urilor să ajungă la serverul tău. Şi va fi exact aceeaşi situaţie ca înainte.
De fapt nu-i trimiţi nimic, scanner-ul doar citeşte codul HTTP returnat. Dacă nu e 200, probabil merge mai departe, nici nu se sinchiseşte să vadă ce-i cu redirectul.
Cum sa nu aiba de unde stie? Ce ti se pare atat de dificil in a detecta un comportament de scan?
Faptul ca acelasi IP face request la fiecare secunda catre fisere inexistente, cu atat mai mult daca asta se intample pe fondul la un spike de bandwidth, nu ar putea sa-ti dea de gandit?
Cu atat mai mult ca vorbim de CloudFlare care are access la o tona de date.
How Cloudflare Detects Bots
Cloudflare’s secret sauce (ok, not very secret sauce) is our vast scale. We currently handle traffic for over 20 million Internet properties ranging from the smallest personal web sites, through backend APIs for popular apps and IoT devices…
This scale gives us a huge advantage in that we see an enormous amount and variety of traffic allowing us to build large machine learning models of Internet behavior. That scale and variety allows us to test new rules and models quickly and easily.
Also
Cloudflare uses Threat Scores gathered from sources such as Project Honeypot, as well as our own communities’ traffic to determine whether a visitor is legitimate or malicious. When a legitimate visitor passes a challenge, that helps offset the Threat Score against the previous negative behavior seen from that IP address. Our system learns who is a threat from this activity.
Trecand peste faptul ca era o gluma, ma refeream sa-i trimiti 2 request-uri inapoi, nu 2 response-uri (nici nu ar fi posibil asta, dar asa rezulta din mesajul tau).
Oare cum ar fi sa ataci cu response-uri? :))
Trecand si peste asta, stii tu cum e configurat si ce webserver foloseste scanner-ul? Stii cum arata codul? Cum scannerul nu stie nimic despre tine, asa nici tu nu stii mare lucru despre el. Prin urmare, nu trebuie sa fii descurajat.
Faptul că un IP face jdemii de requesturi nu prea înseamnă mare lucru. Poate fi pur şi simplu o reţea mare în spatele unui carrier-grade NAT. Şi nu e niciun spike de bandwidth, request-urile HTTP sunt foarte mici, cateva zeci-sute de bytes. 10 req/s înseamnă in 1kB/s. “Paravanul” nici nu-l va remarca
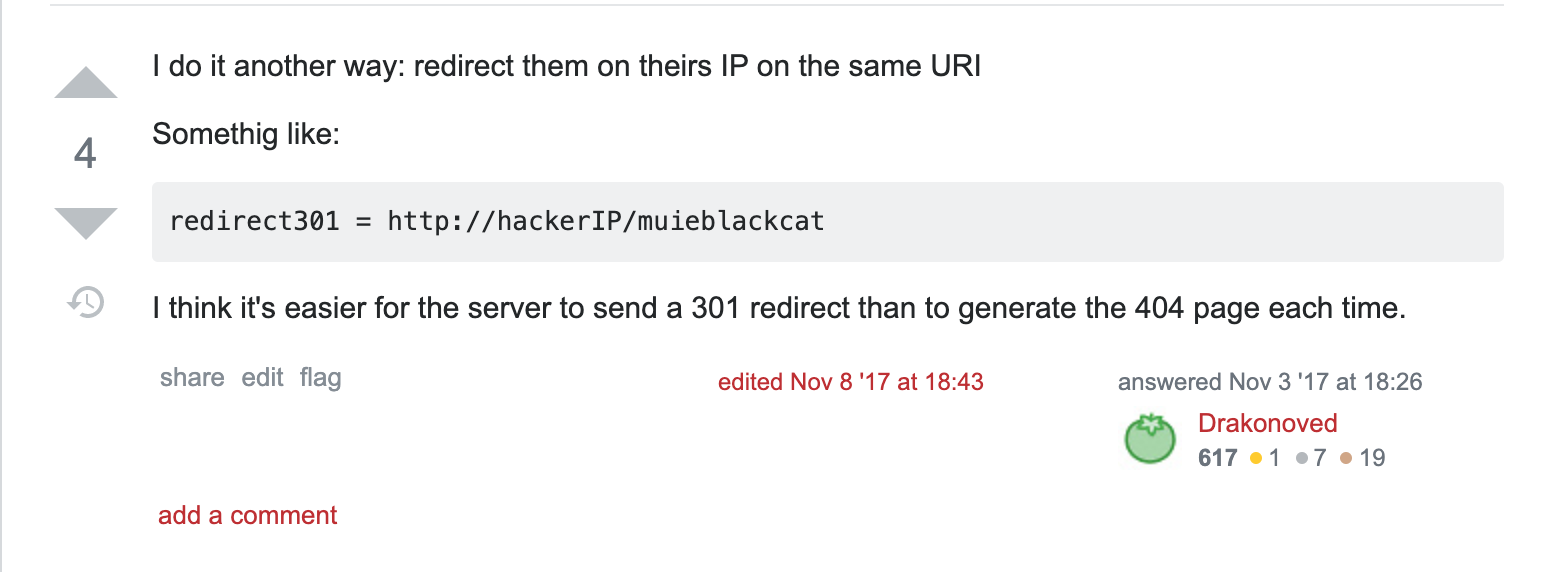
Ziceai de 301, redirect. Request-uri oricum nu ai cui să-i faci. În primul rând, cel mai probabil e o maşină infectată, deci în cel mai rău caz l-ai afecta pe amărâtul care deja e virusat. În al doilea rând, cel mai probabil scanner-ul este în spatele unui NAT, deci nu ai avea să-l “atingi” direct, te-ai “lovi” de router-ul lui.
Scanner-ul este un client care emulează un browser, nu e webserver.
Senzaţia mea este că multă lume confundă denial-of-service-urile de tip “flood” (care încearcă să înece destinatarul cu pachete aleatoare UDP sau syn-uri TCP, eventual spoofate, de nici nu găseşti expeditorul, pentru că acestea nu aşteaptă răspuns) cu scan-urile brute-force. Scan-urile brute-force nici măcar nu trebuie să fie 10 req/s, pot să fie şi 1 request pe zi.
La fel de păcătoase sunt reflected-DoS-urile, în care fără să vrei eşti participant activ la atacurile de tip flood. Cine admiminstrează servere DNS probabil ştie despre ce vorbesc. Sau ar trebui să ştie
Cel mai probabil e un bot care scaneaza dupa fisiere interesante sau path-uri folosite de tehnologiile care au vulnerabilitati publice (Ex: pathbrute/exploitdb_all.txt at master · milo2012/pathbrute · GitHub lista cu toate path-urile extrase de pe exploit-db.com). Tehnica se numeste “directory bruteforce” si e o parte importanta a fiecarui audit de securitate.
Daca ai totul up-to-date si nu expui fisiere “vulnerabile” (Ex: dump.sql cu toate datele userilor, un file upload prin care iti mai urci tu fisiere pe host, etc) nu ai de ce sa-ti faci griji.
Ca sa blochezi genul asta de practici poti sa introduci rate limit pe requesturi, la fel cum a specificat @serghei sau sa instalezi un WAF care poate detecta directory bruteforce (Ex: Sucuri WAF).
Scannerele pentru directory bruteforce detecteaza paginile care afiseaza acelasi raspuns (bazat pe mai multe criterii cum ar fi status code, content-length, headere, etc) si le ignora automat, deci nu prea functioneaza treaba cu redirectul.
E foarte simplu de detectat. Daca un IP face mai multe requesturi 404 consecutive intr-un timp foarte scurt, atunci e brute-force si poate fi blocat.
Nu e nicio masina infectata. Poti face asta cu un server de 5 usd, un tool de directory bruteforce (gasesti pe github destule) si un script bash care ia fiecare IP si il verifica daca are portul 80/443 deschis.
Nu sta nimeni sa faca bruteforce cu 1 request pe zi/ora/minut cand ai o lista de 100k fisiere (100k e un dictionar mediu).
Apropo de asta, mi-am dat seama că de fapt s-ar putea să nu ajute cine ştie rate limit-ul dacă ai activat pe server keep-alive-ul (care probabil este activ by default cam pe toate serverele http). Pentru că atacatorul va refolosi conexiunea şi atunci firewall-ul nu are cum să-şi dea seama câte request-uri au fost.
Well, ăsta e pariu cam riscant. Dacă te bazezi doar pe criteriul ăsta există riscul să blochezi un crawler al motoarelor de căutare. În plus, atacatorul poate folosi tehnici evazive, alternând pagini existente cu inexistente, variind perioada dintre request-uri etc.
De ce să dai bani pe ceva ce se poate obţine gratis sau chiar să rişti să fii identificat?
N-aş fi aşa sigur. Nu am verificat serverele mele http, dar în logurile serverului de email e plin de “atingeri” din astea suave. Mai o conectare/deconectare (probabil testează dacă portul 25 e deschis), ba o încercare sporadică de autentificare etc. Probabil în cele din urma tot va găsi un user cu parola 1234 sau aceeaşi cu numele utilizatorului. Până la urmă sunt nişte automate, au răbdare infinită
De acord. Eficienta rate limit-ului e discutabila.
Singura situatia care imi vine in minte prin care poti confunda un crawler cu un directory bruteforce e atunci cand crawlerul genereaza foarte multe 404. Ca sa se intample asta, ar trebui sa ai pe site foarte multe linkuri 404, ceea ce nu cred ca e cazul pentru @mirceaciu.
Se pot folosi tehnici evazive, dar in general directory bruteforce-ul e noisy si se pot observa usor pattern-uri.
Directory bruteforce-ul in sine nu este ilegal. Se poate face si cu scop de research.
Eu ma refeream strict la directory bruteforce. In general, dictionarele pentru asa ceva sunt foarte mari (cu cat mai mari, cu atat iti cresc sansele sa gasesti ceva interesant). Daca faci 1 req/min, ti-ar trebui ceva ani buni sa testezi 100 target-uri.
Bruteforce-ul pe SSH/FTP/SMTP e diferit (si ilegal). Acolo poti fi detectat si blocat mult mai usor, motiv pentru care atacurile nu sunt asa noisy.