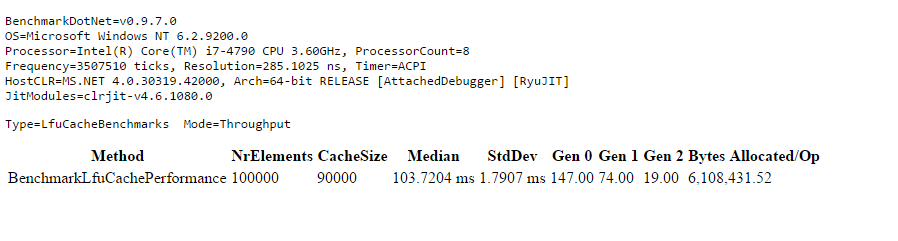
In .NET Framework nu exista un caching care sa implementeze algoritmul least frequently used pentru eliminarea elementelor cel mai putine accesate atunci cand acesta ajunge la dimensiunea maxima.
O posibila solutie pentru implementarea algoritmului least frequently used, se construieste o lista inlantuita(lfuList) a elementelor din cache(CacheNode) ordonata dupa numarul de accesari a fiecarui element(UseCount), de fiecare data cand un element din cache este accesat se incrementeaza numarul de accesari(UseCount) pentru acest element, iar elementul se repozitioneaza in lista inlantuita(lfuList) astfel incat ca elementele din aceasta lista inlantuita sa fie ordonate dupa numarul de accesari, cand adaugam un nou element in cache dar acesta a ajuns la dimensiunea maxima se elimina primul nod din lista inlantuita(lfuList), acesta fiind cel mai putin accesat, de asemenea acesta se sterge si din cache lasand loc noului item.
Urmatorul cache este implementat pentru a fi folosit intr-o aplicatie single thread, pentru o aplicatie multithreading acest cache trebuie adaptat pentru a asigura accesul thread safe concurent la date.
public class LfuCache<TKey, TValue>
{
private class CacheNode
{
public TKey Key { get; set; }
public TValue Data { get; set; }
public int UseCount { get; set; }
}
private readonly int _size;
private Dictionary<TKey, LinkedListNode<CacheNode>> _cache = new Dictionary<TKey, LinkedListNode<CacheNode>>();
private LinkedList<CacheNode> _lfuList = new LinkedList<CacheNode>();
public LfuCache(int size)
{
_size = size;
}
public void Add(TKey key, TValue val)
{
TValue existing;
if (!TryGet(key, out existing))
{
var node = new CacheNode() { Key = key, Data = val, UseCount = 1 };
if (_lfuList.Count == _size)
{
_cache.Remove(_lfuList.First.Value.Key);
_lfuList.RemoveFirst();
}
var insertionPoint = Nodes.LastOrDefault(n => n.Value.UseCount < 2);
LinkedListNode<CacheNode> inserted;
if (insertionPoint == null)
{
inserted = _lfuList.AddFirst(node);
}
else
{
inserted = _lfuList.AddAfter(insertionPoint, node);
}
_cache[key] = inserted;
}
}
IEnumerable<LinkedListNode<CacheNode>> Nodes
{
get
{
var node = _lfuList.First;
while (node != null)
{
yield return node;
node = node.Next;
}
}
}
IEnumerable<LinkedListNode<CacheNode>> IterateFrom(LinkedListNode<CacheNode> node)
{
while (node != null)
{
yield return node;
node = node.Next;
}
}
public TValue GetOrDefault(TKey key)
{
TValue val;
TryGet(key, out val);
return val;
}
public bool TryGet(TKey key, out TValue val)
{
LinkedListNode<CacheNode> data;
bool success = false;
if (_cache.TryGetValue(key, out data))
{
var cacheNode = data.Value;
val = cacheNode.Data;
cacheNode.UseCount++;
var insertionPoint = IterateFrom(_lfuList.First).Last(n => n.Value.UseCount <= cacheNode.UseCount);
if (insertionPoint != data)
{
_lfuList.Remove(data);
_lfuList.AddAfter(insertionPoint, data);
}
success = true;
}
else
{
val = default(TValue);
}
return success;
}
}