Am acest query si ma intereseaza sa aflu cum l-as putea optimiza.
SELECT * AS dsp FROM data_storage_payroll
WHERE file_id = 1
AND (SELECT COUNT(*) FROM data_storage_payroll
WHERE file_id = 1
AND employee_first_name = dsp.employee_first_name AND employee_last_name = dsp.employee_last_name
AND transaction_amount = dsp.transaction_amount
AND ABS(DATEDIFF(dsp.transaction_date, transaction_date)) <= 7
) >= 2
Ce face acest query: selecteaza toate row-urile care mai au cel putin un duplicate dupa coloanele employee_first_name, employee_last_name, transaction_amount,
indeplinind, in acelasi timp, si conditia asta: ABS(DATEDIFF(dsp.transaction_date, transaction_date)) <= 7
Evident, solutia cu GROUP BY, e prima care-ti vine in minte, dar problema e ca eu am nevoie de toate row-urile, nu sa fie grupate.
Am incercat si alte variante, cu JOIN, dar, ori nu-mi returneaza numarul de row-uri corect, ori dureaza tot cam atat.
Mai sunt si alte query-uri pe care vreau sa le optimizez, dar pentru inceput, l-am postat doar pe acesta.
Cred ca mai trebuie niste informatii. Poate sunt niste optimizari OK de facut, dar se poate sa fie si optim query-ul si nu mai ai ce sa-i faci.
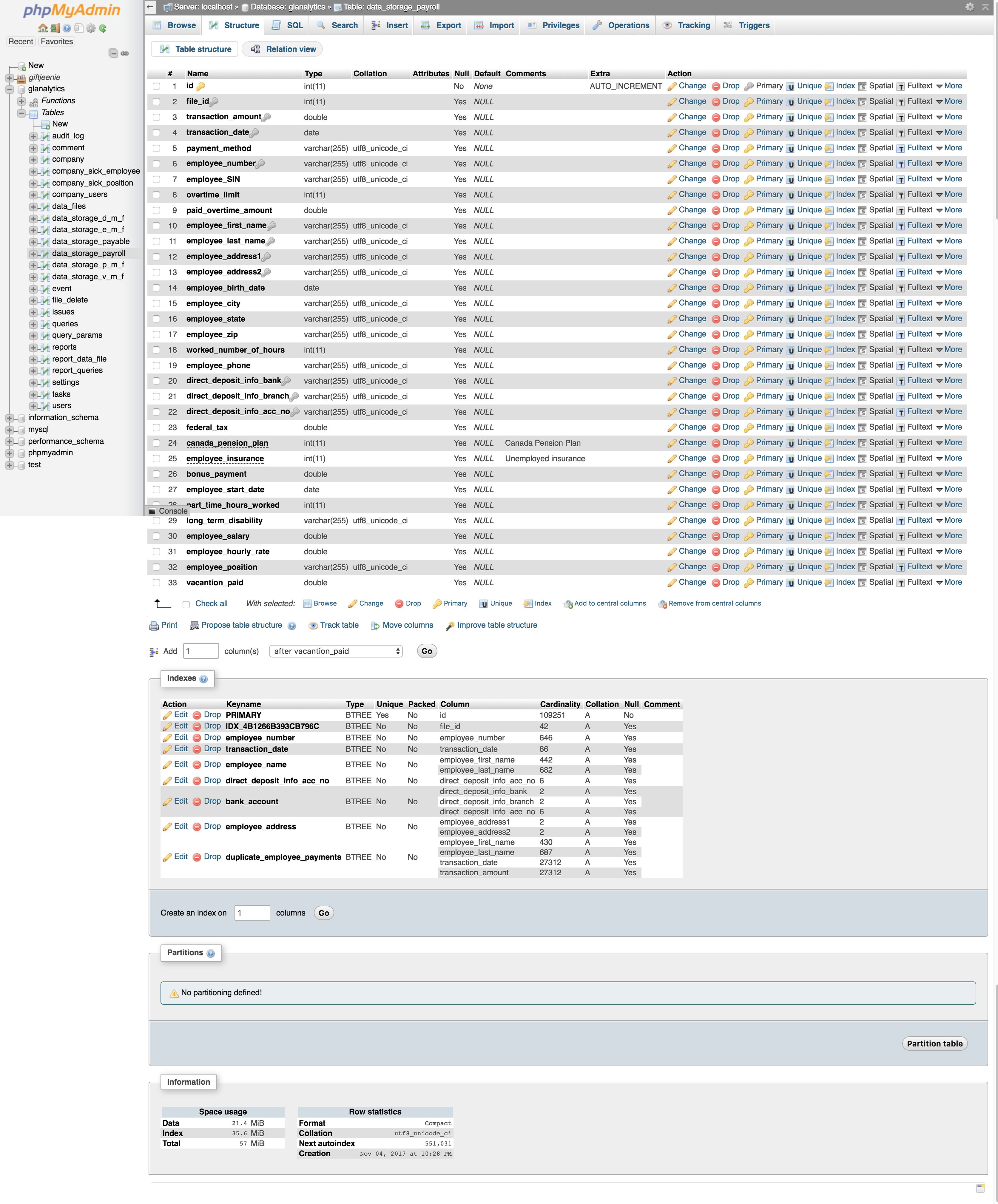
Cat de incet merge acum si cat de repede vrei sa mearga? Ce fel de indexi ai pe tabela? Cat de mare e tabela? Care-i structura tabelei in rest (macar un hint de schema, daca nu toate coloanele). Vre-un output de la query planner ceva ca sa vezi unde isi bate capul MySQL cu query-ul asta?
Un query de genul asta se poate structura si ca un self join, desi as zice ca MySQL o sa aduca query-ul tau la o forma echivalenta.
E destul de greu să dăm sfaturi fără să știm structura datelor, ce reprezintă sau ce anume vrei să obții[1]. La fel cum a zis și @tekkie, structura și indecșii ar ajuta mult. Fără să avem informațiile astea putem doar să ne dăm cu presupusul.
Așa că eu presupun că tabela are un PRIMARY KEY de care te poți folosi și să încerci faci un LEFT JOIN cu care să verifici dacă mai există înregistrări care să respecte criteriile tale. LEFT JOIN poate fi mai rapid decât un subquery.
Te mai poți folosi și de faptul că tu verifici să existe minim 2 tranzacții și să eviți să folosești COUNT. În cazul tău e de ajuns să găsești încă o înregistrare diferită (PRIMARY KEY diferit) și să verifici cu IS NOT NULL.
Dacă 2 e un număr care e variabil poți încerca să folosești LEFT JOIN cu GROUP BY și HAVING.
[1]Tu practic ne întrebi cum poți optimiza doar o mică parte din soluția ta. De multe ori poți primi recomandări cu abordări diferite la problema mai mare pe care încerci să o rezolvi și din care să rezulte în soluții mai simple/mai eficiente.
SELECT dsp.id, dsp.employee_last_name, dsp.transaction_date FROM data_storage_payroll dsp
WHERE dsp.file_id = 1
AND (SELECT COUNT(dsp_inner.id) FROM data_storage_payroll dsp_inner
WHERE dsp_inner.file_id = 1
AND dsp_inner.employee_first_name = dsp.employee_first_name AND dsp_inner.employee_last_name = dsp.employee_last_name
AND dsp_inner.transaction_amount = dsp.transaction_amount
AND ABS(DATEDIFF(dsp.transaction_date, dsp_inner.transaction_date)) <= 7
) >= 2
Am rugamintea sa ne dai un analyze/explain pe subquery, deci pe
SELECT COUNT(dsp_inner.id) FROM data_storage_payroll dsp_inner
WHERE dsp_inner.file_id = 1
AND dsp_inner.employee_first_name = dsp.employee_first_name AND dsp_inner.employee_last_name = dsp.employee_last_name
AND dsp_inner.transaction_amount = dsp.transaction_amount
AND ABS(DATEDIFF(dsp.transaction_date, dsp_inner.transaction_date)) <= 7
evident punand o valoare in loc de dsp.transaction_date si respun cel e mai folosesti din outer
Contrar așteptărilor, * in contextul countului se comportă diferit față de cum se comportă în general, unde într-adevăr sunt de acord cu ce ai spus. Trebuie să ne ferim de * in orice împrejurare, mai puțin în contextul countului. Sunt mai multe discuții pe tema asta, dar ideea este că în unele cazuri (depinde de indexi, de tipul coloanei, de tipul bazei de date) count(*) este mai rapid decât count(coloană).
Adevărat, sunt multe cazuri (și aici vorbind și de alte DB-uri), de aia am vrut să scot în evidență că acel * de la count se comportă puțin diferit față de “SELECT *” și că trebuie avut grijă și studiat puțin (pentru că merită!).
Urmăresc forumul și m-am gândit că ție nu-ți scapă chestia asta, am răspuns pentru lumea care citește
Query-ul tău este aproape “optimizat la maxim”, lipsind doar ce a spus @Luxian. Tu ai nevoie de count(*) > 2, nu ai nevoie de rezultatul countului, ceea ce înseamnă că la primul row pe care-l găsește trebuie să se oprească, nu să caute în continuare.
Dacă asta nu te ajută, înseamnă că trebuie să intervii la structura datelor. Aici mă refer la indexi sau la structura tabelelor.
De ce spun asta? pentru că oricum ai scrie queryul respectiv, DB-ul trebuie să facă asta:
Care se traduce neapărat într-un scan a 3 coloane (2 varchar și 1 dată). Din căte văd, data este indexată, ceea ce este bine, dar căutarea după 2 varchar neindexate este grea, oricum ai scrie query-u, baza de date trebuie să se ducă row cu row să caute dacă există first_name = first_name și last_name = last_name, care este slow. Nu poți să schimbi asta decât prin indexi sau prin altă structura (o coloană în plus? să scoți first_name si last_name într-o tabela separată? sau alte idei care ți se potrivesc).
În funcție de ce alte query-uri mai faci pe tabela respectivă, poate merită să pui un index pe (first_name, last_name), sau poate doi indexi, unul pe first_name, altul pe last_name. Sau, cum ziceam mai sus, poate merită să scoti first_name și last_name într-o tabelă separată și să fie legat de tabela ta prin foreign_key.
Să ai grijă și la indexi, pentru că au și bune, și rele. Citește putin despre ei, încearcă să pui unde crezi că se potrivesc mai bine și fă niște teste.
TL;DR
Ce spunea și lumea, e greu să ne dăm seama de o soluție mai bună pentru că ne lipsesc date, dar problema ta se rezuma la o căutare în baza de date după 2 coloane varchar neindexate care trebuie făcută oricum ai scrie queryul (imposibil să faci altfel dacă nu modifici structura / indexi), singura optimizare este că poți să faci “exists” și nu “count(*) > 2” pentru că nu te interesează numărul și atunci el poate să treacă mai departe când găseste primul row care îți îndeplinește condiția (optimizare destul de bună). Dacă vrei mai mult: indexi sau structura tabelelor diferite.
ontopic, cand ai subquery-uri complicate cea mai buna solutie e sa faci cache (ma refer la coloana separata cu rezultatul subquery-ului) la rezultate (presupun ca n-ai pretentie de realtime absolut). Altfel merg ordonarile si ce mai vrei tu dupa aia.