Hello,
Am facut cateva experimente cu UI Path document understanding data labeling incat sa incerc sa antrenez un model folosind interfata web. Acesta model de PDF este unul din mai multe. Motiv pentru care incerc o varianta cu AI.
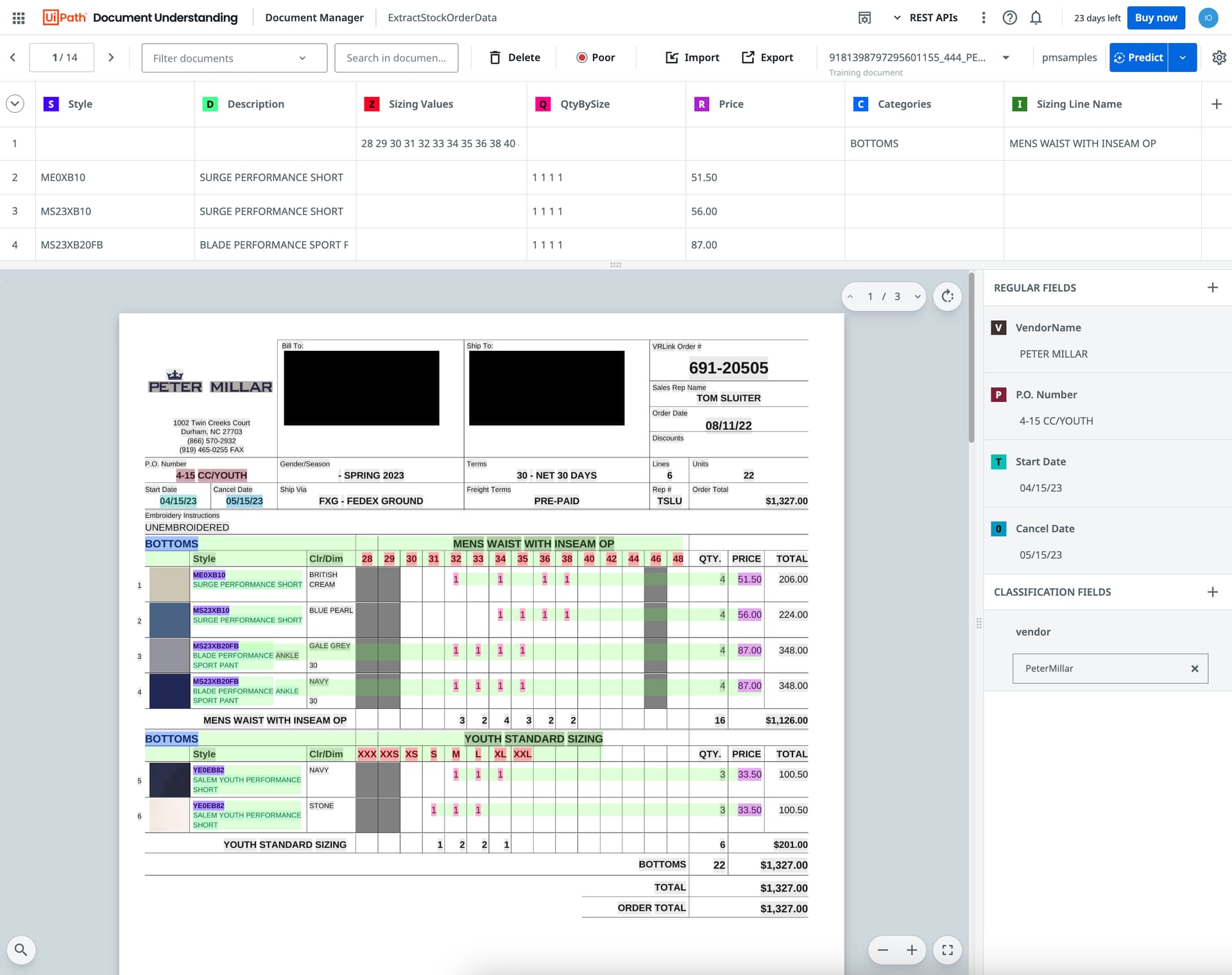
Documentele in cauza sunt PDF invoices cu o structura ca cea de jos, cu o structura nested dar relativ constanta: header + tabele per categorie continand itemuri cu diverse cantitati pe dimensiune.
As avea cateva intrebari:
- Pare doable antrenarea cu Document Understanding a unui PDF asa complex ?
- Pare ca se confuzeaza din cauza faptului ca categoria si dimensiunile apar ca un rand cu format diferit de items. Exista un process similar cu acesta mai robust in uipath.
- Exista mai multe tabele pe pagina. Exista posibilitatea sa segmentez documentul in tabele incat sa fie mai clar pt algoritm unde incepe si se termina lista.
- In screenshotul de jos pare ca trebuie sa antrenez undeva la 1600 de document pt usecase-ul acesta. Sa fie o estimare exagerata. Any tips on decreasing that?
- Pt cateva sute de documente avem deja facut data entry precis intr-o structura de date pe categories, dimensiune, etc. Exista vreo modalitate de antrenare supervizata a unui model in UI path pe baza de input(PDF) - output pairs(o structura de date extrasa manual).
- Sugestii de tool-uri similare pe care le pot incerca sa vad ce pot face (am incercat parsio.io si inca cateva)
- Alte sugestii de componente sau workflowuri care ar fi mai potrivite intr-un astfel de use case…

PS. Incerc sa explorez diverse solutii fara asteptari prea mari. So far UIpath si parsio. Rezultatele sunt mai bune decat ma asteptam dar inca departe.
Mersi pt orice raspuns!