Despre LoadBalancer, High Availability si Failover.
Cea mai simpla diagrama de arhitectura pentru LoadBalancing arata cam asa:
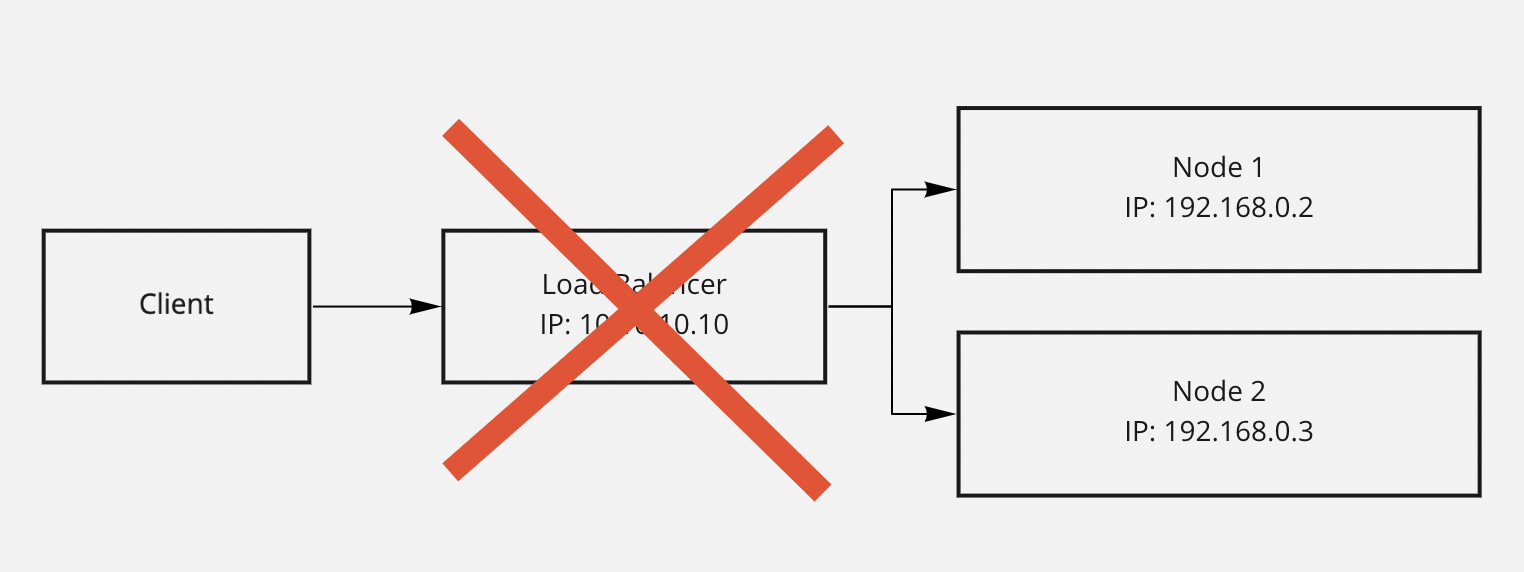
Prin urmare, tot timpul am avut senzatia ca acea componenta de LoadBalancer e, de fapt, un server separat, care trebuie sa aiba un IP separat. Altfel, cum ar sti clientul catre ce IP sa trimita request-urile ?
Intrebarea care tot imi venea si nu-i gaseam raspuns: “Ce se intampla daca serverul de LoadBalancing cade, respectiv IP-ul 10.10.10.10 devine indisponibil?”
Unde ajung request-urile? Ce se intampla cu ele? Despre ce High Availability vorbim daca avem un Single Point of Failure?
Abia azi avea sa aflu despre notiunea de Virtual IP / Floating IP. Totodata sa aflu ca acea componenta de LoadBalancer nu exista ca si un server separat, care sa aiba un IP separat.
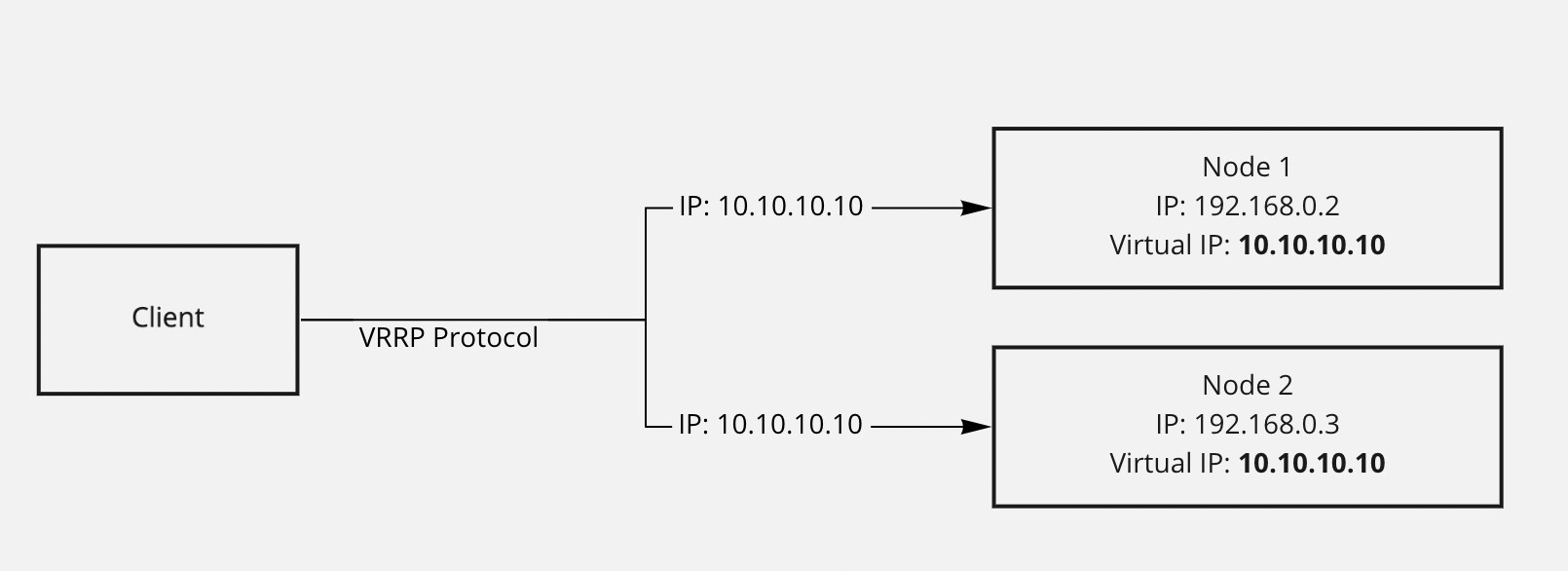
De fapt, diagrama arata in felul urmator, din punctul de vedere al node-urilor:
Ca mai multe node-uri sa aiba acelasi (Virtual / Floating) IP, se datoreaza protocolului VRRP (Virtual Router Redundancy Protocol)
De fapt, doar un singur node poate avea asignat acel Virtual IP, la un moment X. Restul node-urile doar au predispozitia de a primi acel IP, in mod automat, in caz ca node-ul principal cade. Acest proces se numeste failover si de el este responsabil utilitarul keepalived.
Cum afla restul node-urile cand un node a cazut? Dandu-si ping-uri, in mod constant, unul altuia, iar cand unul nu mai raspunde, e clara treaba.
Pana la etapa aceasta, folosind keepalived (bazat pe protocolul de VRRP) obtinem doar partea de High Availability.. Asta presupune strict faptul ca ori cate ori am sa trimit un TCP packet catre un IP, cineva o sa-mi raspunda (chiar daca pot fi servere diferite, care fac asta).
Mai departe, intra notiunea de LoadBalancer care se configureaza peste keepalived.
LoadBalancer-ul va fi prezent, la fel ca si keepalived, pe toate node-urile. Aplicatia de LoadBalancer, va culege de pe fiecare node pe care este instalat, informatii legat de load-ul (RARM/CPU usage) acelui node si i le va comunica restul node-urilor.
In functie de strategia de LoadBalancing aleasa in configuratie (roundrobin fiind cea mai populara, care presupune distribuirea in mod egal a load-ului) se vor distribui request-urile.
Chiar daca instantele de LoadBalancer sunt pe o linie orizontala, exista totusi, un elected leader, adica un master. In cazul in care master node-ul cade, atunci clusterul stie sa-si aleaga un nou leader, care va fi responsabil de distribuire request-urilor.
Un tutorial bun, care imbina toate aceste concepte la un loc, este acesta: