Buna. Pornesc acest topic in ideea de a mai reveni asupra lui si cu alte ocazii, cand va fi nevoie sa discutam despre arhitectura aplicatiilor software, in special zona web, atat moduri de abordare, cat si cazuri mai concrete.
Sunt acum in situatia in care trebuie sa gandesc arhitectura, respectiv sa fac si o reprezentare grafica a ei, a unei aplicatii web de document/content management (similara cu asta), care trebuie sa fie scalabila, evident.
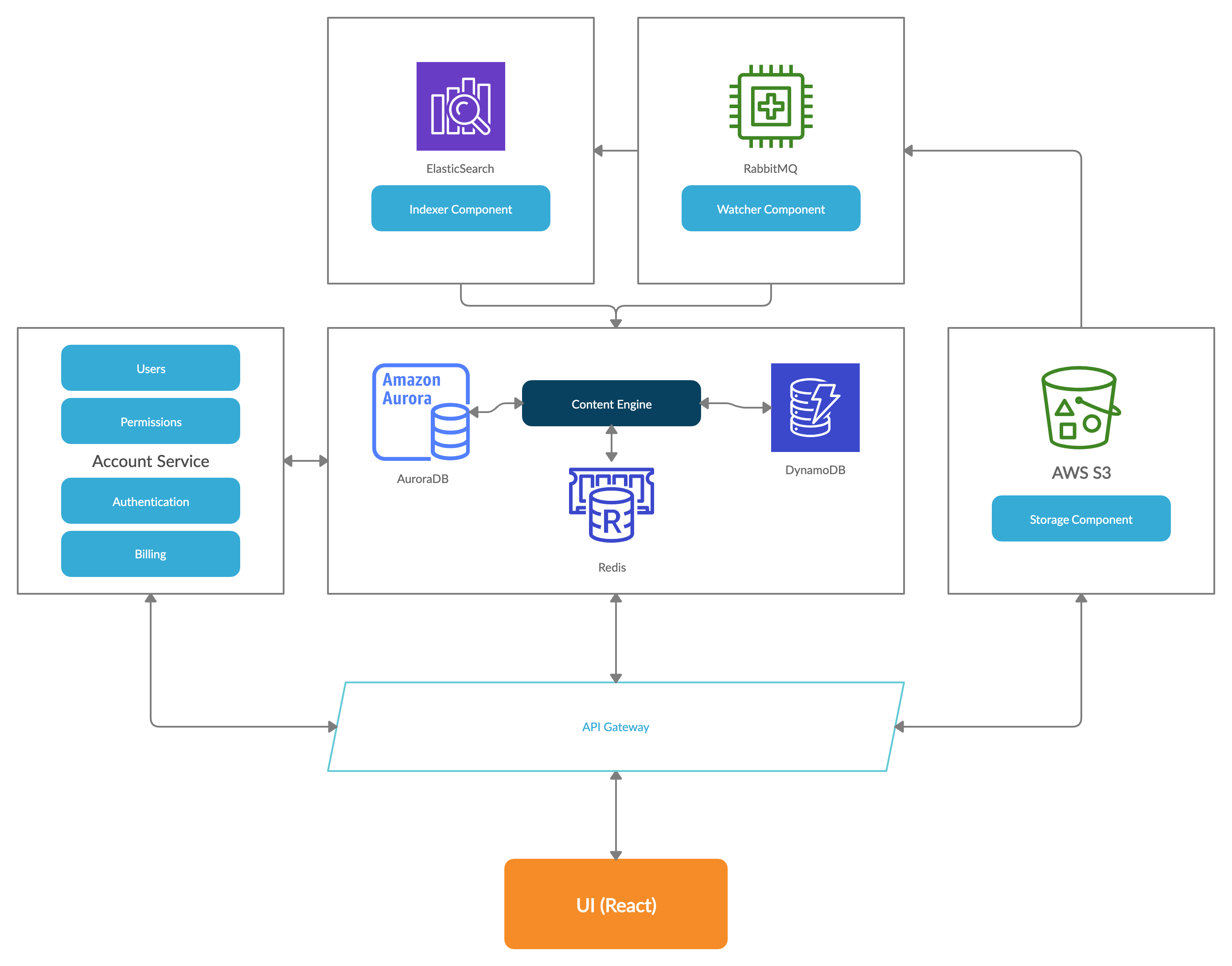
Aici e reprezentarea grafica ce am incercat-o (folosind tool-ul creately.com).
Prima data, as incepe development-ul cu Heroku pentru ca se configureaza usor CI/CD-ul. Ulterior as migra spre AWS (cand si arhitectura/infrastructura va fi ceva mai clara), dar as incerca sa evit serviciile lor specifice, pentru a nu fi dependent de un anume cloud service (AWS vendor lock-in).
As dori niste sfaturi in legatura cu aceasta arhitectura aleasa, reprezentarea ei si modul de abordare.
As dori, in general, niste resurse de unde ma pot inspira, in directia asta. Stiu de stackshare.io , dar m-ar ajuta sa vad si niste grafice, ca sa inteleg mai bine cum comunica toate aceste servicii intre ele, respectiv cum ar trebui configurate node-urile/pod-urile.
Trebuie sa poata opera cu un numar de documente/content-uri de ordinul, sa zicem, sutelor de milioane, in conditii normale, fara sa se blocheze. Asta ar fi obiectivul final. Evident, nu cred ca are rost de implementat toata aceasta complexitate inca de la inceput, dar, cel putin, ar trebui pregatit locul pentru a putea fi implementata ulterior.
E bine sa pornesti de la niste presupuneri, oricat de absurde ti s-ar parea. E un exercitiu interesant. Sa zicem:
10 milioane de useri in total.
Un user are in medie 200 de fisiere. M-am uitat la mine in dropbox. Numarul asta modifica-l dupa cum crezi tu de cuviinta.
marime fisier in medie este de 500kb. Docs mainly.
Asta ar rezulta in 2 miliarde de documente stocate cu un storage total de 1 petabyte.
Pentru bandwidth si GET/POST/PUT/DELETE requests calculeaza un maximum de 10% useri activi daca ai succes. E ok sa ai ambitii mari insa se poate gandi o arhitectura care sa scaleze orizontal relativ ok chiar si la 50 de mil useri activi in conditii similare.
Design high-level:
Practic vei stoca efectiv fisiere si probabil metadata gen filename, marime, versiune, etc. Probabil si persoanele cu care acestea sunt share-uite.
Nici nu te gandi la vendor lock in aici la nivelul asta. Nu ai problemele alea deocamdata. Ai doar storage in cloud. Il poti muta in cateva saptamani daca e neaparata nevoie.
Readurile si write-urile intr-un astfel de sistem sunt similare, dar am putea sa presupunem un 60 reads-40 writes pentru un calcul ulterior AWS, Azure, Google Cloud.
Componente:
metadata db(SQL), unde o sa stochezi informatii despre fisiere, versiunile lor, locatia in filesystem, etc.
o componenta watcher va monitoriza fisierele urcate si va notifica printr-un event o alta componenta de orice actiune ce o va face userul, gen create, delete, update fisiere. Ar trebui sa iei in calcul si folosirea unui sistem de queue aici gen RabbitMQ, ActiveMQ, poate chiar si Kafka alegerea e a ta, fa un research.
o componenta Indexer proceseaza eventurile primite de la watcher asyncron actualizand baza de date, notificand userul/userii de eventuale modificari ale fisierului, emails, analytics, etc.
O componenta chunker care la upload de fisier va “sparge” fisierul in mai multe bucati pe care le va urca una cate una. La un eventual upload fail, acesta putand relua upload-ul de la o anumita bucata, si nu de la 0.
Trebuie sa ai in vedere:
Duplicarea datelor.
Sunt anumite tehnici pe care le poti folosi pentru a optimiza storageului prin calcul de hash-uri, etc. De exemplu, poti stoca initial fisierele si verificate post-upload contra duplicarii in sistem si eventual sterse cele duplicat. Aici avantajul este ca clientul nu asteapta dupa un calcul de hash, insa dezavantajul este ca TOT vei stoca duplicate o perioada de timp pana vei face cleanup, consum de bandwidth, etc.
Alt exemplu tot aici ai putea verifica hash-urile real time, insa ele ar trebui stocate in memorie pentru un acces rapid. De revenit aici.
Caching. Nu prea sunt multe de zis aici, e oarecum dificil de implementat pe un astfel de proiect un caching care chiar sa ajute, dar sa zicem ca cumva identifici fisiere “hot”, care sunt uploadate de multi useri intr-o perioada scurta de timp(calcul de hashing again) si poate mai important, downloadate foarte mult. Ai putea tine asta in memorie insa trebuie avut grija deoarece 1. un server serios pentru caching de tipul asta are un minim 96GB ram, deci costa $$ si 2. un fisier ar putea repede deveni “cold” si caching-ul e degeaba. Trebuie gandit bine un policy gen Least Recently Used (LRU) cache ca sa dai afara repede un fisier “cold”.
Load Balancer, Sharding, Microservices vs Monolith, k8s, etc.
O sa incerc sa imbin un exemplu din experienta mea cu un startup, dar pe ideea de Document Management SaaS. Chiar daca esti tehnic ai nevoie de constrangeri de business reale:
platform operational budget: %40 of MRR (founder decided)
Q: So, how much can I spend on services?
A: €3316 / month for the first quarter
Q: What are the limits of my normal user?
maximum file size: 100MB
maximum available storage: 2GB
ratelimit on uploads: 1 file per second
index for search documents under 20MB
Q: What happens after a user uploads a document, as platform features?
we store the file
we index the content for search, if its under 20MB (I’ll add this above too)
we classify the document based on content (adding meta)
etc.
Platform segments:
storage service
search / indexing service
meta service (classifications, business logic, etc)
accounts service (authorization, permissions, etc)
auth service (authentication)
etc
Requirements per service:
storage
2GB x 500 users => 1TB+ of space
daily document access => 10% of total upload size (we estimate so we can generate bandwidth needs)
etc
auth service
500+ accounts
SMS activation
etc
search / indexing service:
this will have the most expensive needs
parsing files requires high CPU loads
storing large file means large indexes, the DB needs to be fast
etc
Dupa ce ai un overview de “business & platform needs” te poti apuca sa cauti servicii si provideri care se incadreaza in buget.
Presupunem ca alegi AWS pt. storage, 0Auth pt. auth, etc, dupa vezi de ce mai ai nevoie si incepi sa faci un draft pt. serviciile ramase de implementat, la fel, cu parametrii bine definiti.
Nice! practic asta ar fi un minimum de buget cu care sa incepi afacerea.
Eu am facut o socoteala in conditii de succes moderat. Ceea ce evident e un caz ideal dar se intampla rar. In cazul descris de mine, conform AWS calculator, doar storage-ul in S3 ar costa 23k eur pe luna. Probabil ar ajunge la un cost total de 50k euro cu totu, dar la 10M active users, ar putea presupune lejer un 1% paying customers( poate gresesc, ar trebui mai putini?? cineva cu SaaS experience sa ne zica, pls ).
100k paying customers constant la un 4,99$ sa zicem, ca sa fii competitiv, esti pe ++ destul de bine. Ma rog, chiar sunt curios cat % din active users sunt si paying customers intr-un saas ca asta.
Eu o să vorbesc despre elefantul din cameră: baze de date (statefull applications) în Docker / Kubernetes. Nu face asta. Uite aici mai multe explicații. Mai găsești o grămadă de alte exemple dacă cauți.
Docker / Kube sunt ok sa rulezi statelss apps (backend api în diagrama ta). Pentru baze de date (mai ales RDBMS), ori folosești un serviciu hosted (gen RDS) dacă îți permiți și nu vrei să îți bați capul ori folosești niste VM-uri clasice (poți să faci provizionare cu Terraform și configurare cu Ansible pentru o “dockeresque experience”)
Va multumesc mult pentru raspunsurile elaborate si pline de informatii valoroase.
Interesanta abordarea voastra, nu ma gandisem ca la nivelul asta se invart asemenea costuri si ca de la aceste calcule ar trebui pornit cand se face o arhitectura.
@redecs, da, am auzit niste pareri precum ca nu e o idee buna sa tii db-ul in container de docker. Merci de link.
@tacheshun daca in cazul asta, unde avem o cantitate mare de date/documente care nu par foarte relationale, se potriveste mai bine MySQL decat Mongo, atunci unde s-ar potrivi el ? Eu tindeam spre el datorita performantei lui.
Printre altele, as mai initia doua intrebari spre discutie:
Care decizii arhitecturale sunt cel mai greu de remediat? Adica la ce ar trebui sa fim foarte atenti atunci cand pornim structura? Dincolo de limbajul de programare, banuiesc ca ar veni tipul bazei de date si, eventual, framework-ul. Restul, servicii precum ElasticSearch, RabbitMQ, Kafka, Redis banuiesc ca se pot integra/dezintegra mai usor !?
Care e marele atu al serviciilor specifice venite de la AWS (ElastiCache, Aurora, DynamoDB, EKS) ? Cat de mult iti simplifica configurarea? Cat de mult iti afecteaza costurile?
Banuiesc ca nu te-ai uitat pe linkurile de mai sus. E ok. O sa incerc un tldr version.
Probabil o sa ai nevoie de stochezi file chunks la upload. Nu iti trebuie performanta aici. Iti trebuie consistenta. Si probabil o sa ai nevoie ca fisierele tale sa fie sincronizate cand sunt salvate(100%) in S3/Blog storage whatever. Daca vrei sa folosesti mongo, go ahead, dar fa o cu cap, nu il folosi acolo unde ai nevoie de full acid compliant db ca indiferent de laudele celor de la mongo tot nu e ca un rdbms clasic.
Foloseste-l gen materialized view ca asa obtii best of both worlds. Chiar nu vreau sa pornesc un flame war pentru ca si eu folosesc mongo si imi place. Depinde de situatie insa.
Pai sunt fully managed de catre aws. Nu mai trebuie sa platesti o echipa pentru asta doar stii ca cea mai scumpa resursa in ziua de azi este omul. In plus, unele solutii gen Aurora au si o performanta exceptionala.
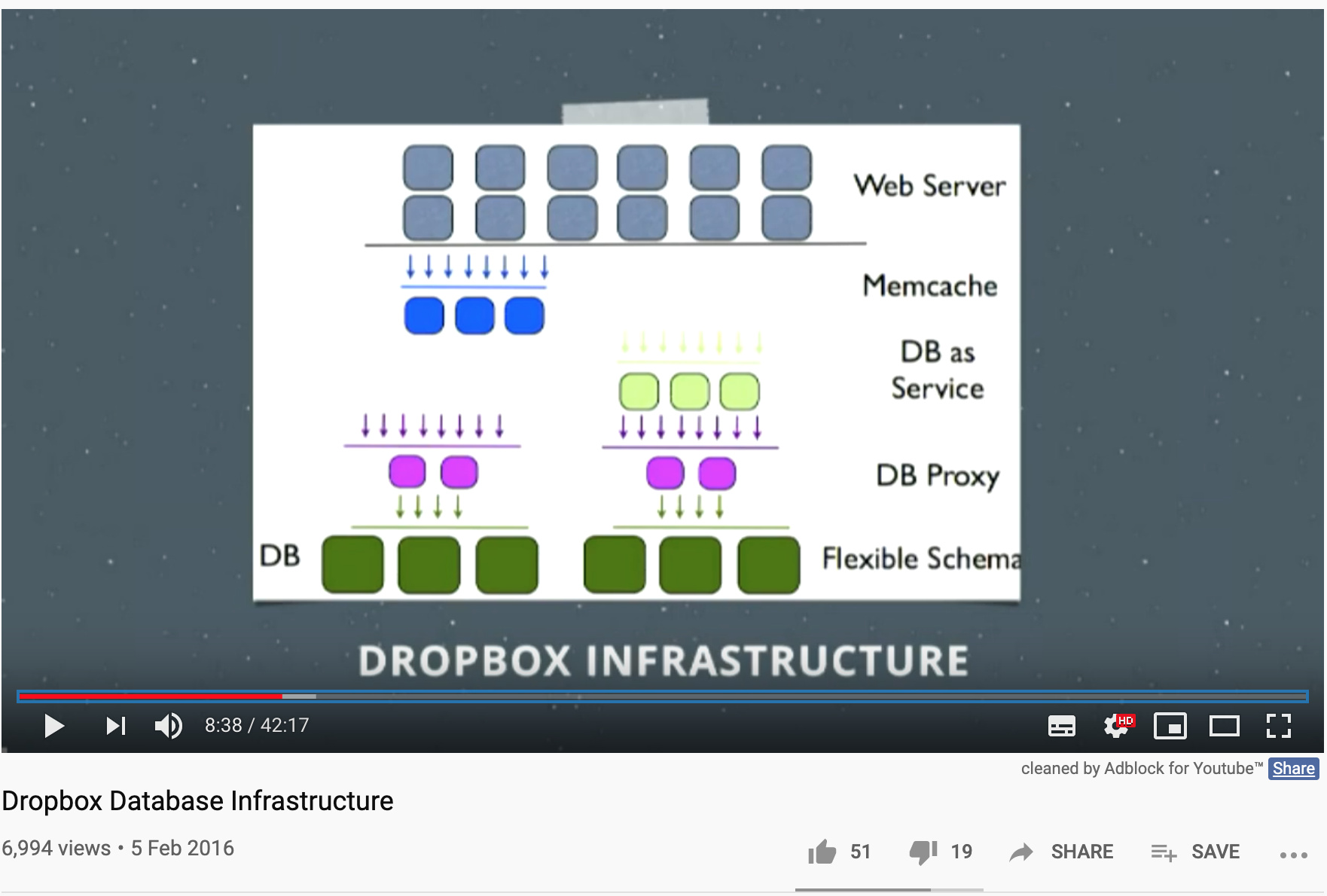
M-am uitat peste link-urile cu dropbox si ei, practic ce au facut, a fost sa faca un wrapper de noSQL (numit Edgestore) peste MySQL.
As vrea sa dezvoltam aici, un pic, ca sa ma asigur ca am inteles bine. Prin consistenta te referi la faptul ca ai nevoie de SQL Transactions ca sa handle-uiesti upload-ul cu file chunks? In caz ca da fail pe la jumate sa poti face rollback? Sau daca nu, la ce te referi mai exact?
Spre ex, ca sa stochez file tree structure impreuna cu metadata pentru fiecare fisier, nu prea vad unde as avea nevoie aici de consistenta. Mai degraba de performanta. Iar cum metadata difera de la un tip de document la altul si nu are nevoie de un fixed schema, mi se pare ca un noSQL de tip document store, precum e MongoDB, se potriveste perfect.
E un ORM custom. Eu nu am inteles ca ar fi un nosql wrapper, dar in fine.
Exact. In situatia asta vei dori sa ai o tranzactie de genul “insereaza-mi toate chunk-urile sau niciunul” pentru ca nu vei dori sa niciun chunk lipsa. Altfel, design-ul componentei pentru management de chunks ar fi degeaba.
Ma rog, asta nu inseamna ca nu iti va merge deloc pe Mongo. Dar ar trebui testat foarte bine pentru consistenta. Ei se lauda ca sunt ACID compliant acum si au performante bune pe inserturi. Fa un POC, ridica-l in azure sau aws, si testeaza mongo sub heavy load.
Daca totusi tii neaparat sa ai nosql si nu te deranjaza cloud-ul, ti-as recomanda Amazon DynamoDB sau Azure CosmosDB.
care spune tipa ca e “… like a noSQL distributed database layer”. Iar jos de tot, unde e “Flexible schema” sunt, de fapt, db-urile de MySQL (aprox. 6000 la numar)
Intr-o alta ordine de idei, o sa incerc sa refac acea diagrama implicand informatiile culese. Multumesc.
As mai avea o intrebare. Credeti ca Node.js s-ar descurca ca backend pentru toata partea asta de file management? Trebuie sa aleg intre Node.js si PHP.
Daca ai nevoie de lucruri complexe pt nodejs ,iti poti scrie in c++ pachete aproape nativ. PHP is a dying breed, mergi oe ceva usor scalabil cu docker.
Limbajul nu conteaza pentru un produs de genul asta cu o arhitectura ca cea de mai sus. Oricare din limbajele mentionate de tine mai sus isi pot face treaba foarte bine.
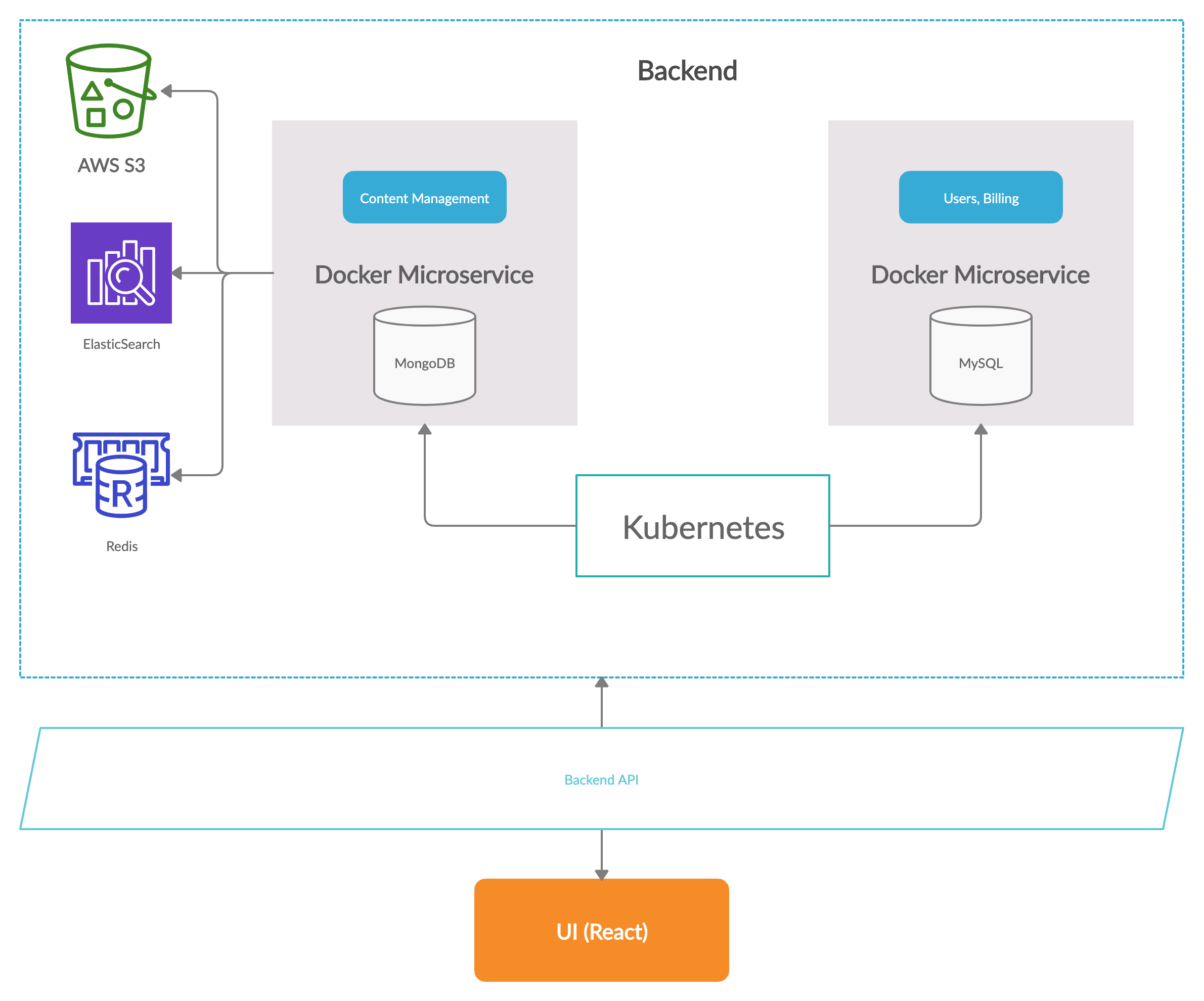
 ).
).